なぜStreamlitでBIダッシュボードを作るのか
従来のBIツールからコードベースへの移行がもたらす変革
はじめに
本書籍は、Squadbase の開発チームによって執筆されています。Squadbaseは、コードベースの社内ツールをデプロイするためのプラットフォームです。コーディングAIを活用して、業務に適した社内ツールを迅速に開発・展開することで企業のデータ活用や生産性改善を支援しています。
本書籍では、全体を通じて「StreamlitでBIダッシュボードを構築」ことに焦点を当てます。
なぜStreamlitでBIダッシュボードを作るのか
データ活用が企業の競争力を左右する現代において、 BI(Business Intelligence) ツールは重要な役割を果たしています。しかし、従来のBIツールには数多くの制約があり、多くの企業がその限界に直面しています。そこで注目を集めているのが、Streamlitを使ったコードベースのBIダッシュボード構築です。
本章では、従来のBIツールが抱える課題を整理し、なぜStreamlitでBIダッシュボードを構築することが現在の最適解なのかを詳しく解説します。
従来のBIツールが抱える課題
カスタマイズ性の乏しさ
従来のBIツールでは、ベンダーが提供した機能を組み合わせるのが精一杯で、独自のカスタムロジックや最新のAIモデルの統合といった高度な要求に応えることができません。特に、現場固有のニーズに合わせたカスタムUIや機能を開発することは困難です。
データソースの制限
BIツールが扱えるデータの形式や量には制限があり、APIリクエストによるデータ取得や大規模なデータセットの取り扱いに制限があります。典型的には、以下の様な問題に当たることがあります。
- ツール側で接続できるデーターベースの種類が限られているため、利用しているSaaSのAPIを直接使えない。
- データ量が大きくなると、パフォーマンスが低下し、ダッシュボードの表示が遅くなる。
- 特殊な階層構造を持つデータ(例:JSONやXML)を扱うのが難しく、データの前処理に時間がかかる。
学習コストの高さ
多くのBIツールのUIは複雑で、非エンジニアが使いこなすためには長期間の学習が必要です。また、ツール固有の操作方法を覚える必要があり、チーム内での知識共有が困難になります。
変更の困難さ
BIツールの機能追加や変更には、専門知識を持つエンジニアのサポートが必要で、迅速な対応が困難です。ビジネス要件の変化に柔軟に対応できず、機会損失につながることがあります。
保守性の低さ
多くのBIツールでは、設定やカスタマイズをGUI上で行うため、変更履歴の管理やバージョン管理が困難です。これにより、変更履歴を追うことが困難になったり、問題発生時のロールバック (前のバージョンに戻すこと) が複雑になります。また、複数環境を運用するための機能が不足していることが多く、多重に保守コストがかかります。
運用コストの高さ
BIツールのライセンス費用は、ユーザー数やデータ容量に比例して増大します。また、専門知識を持つ人材の確保や教育にかかるコストも無視できません。
これらの問題に対処するために、多くの企業はコードベースのアプローチ (BI as Code) を採用し始めています。特に、Streamlitはそのシンプルさと柔軟性から、BIダッシュボードの構築に最適なフレームワークとして注目されています。
Streamlitによるコードベースの解決策
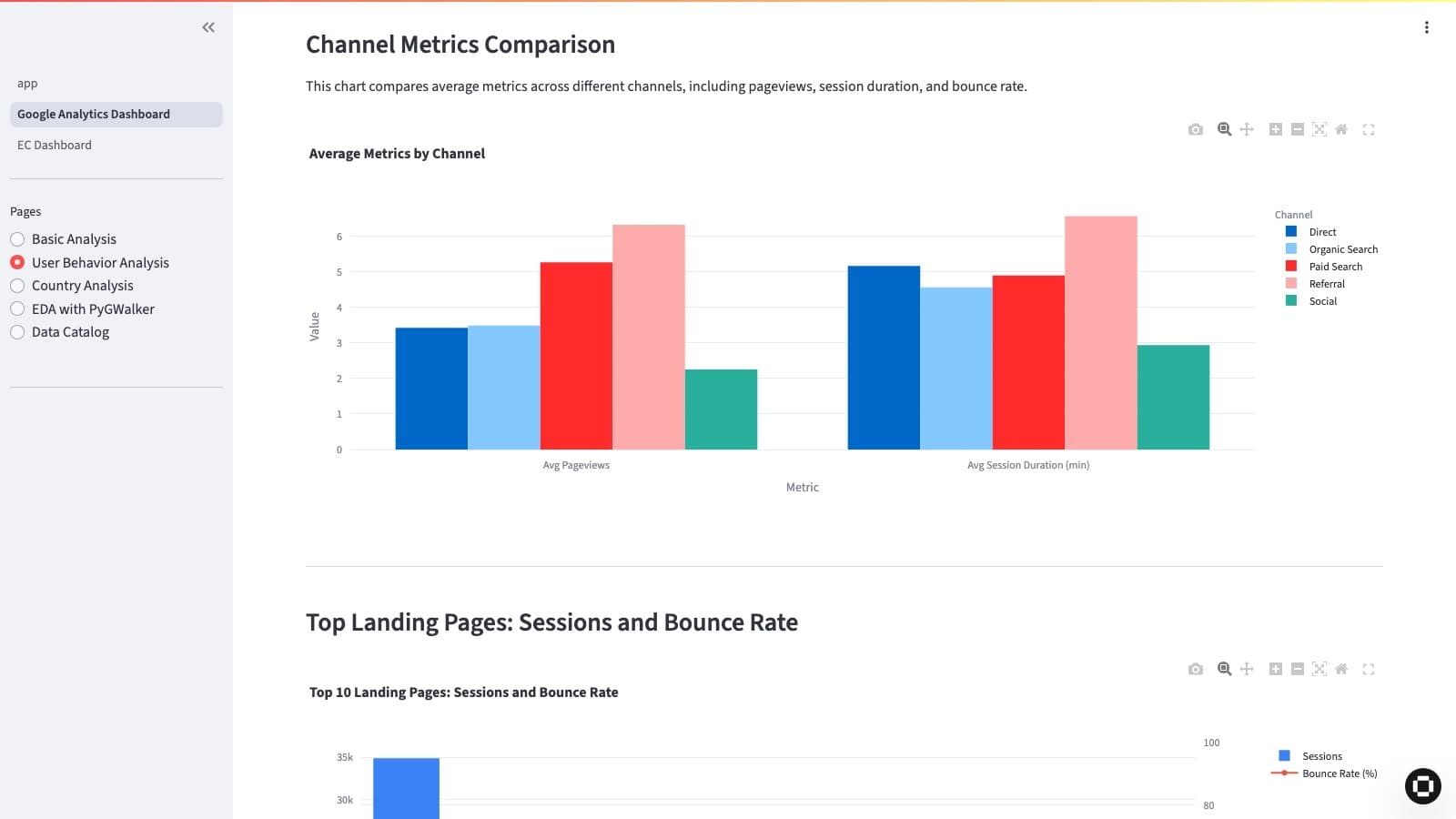
Streamlitとは
Streamlitは、Pythonで書かれたオープンソースのフレームワークで、データアプリケーションを迅速に構築できるツールです。わずか数行のコードで、インタラクティブなWebアプリケーションを作成できる点が最大の特長です。
import streamlit as st
import pandas as pd
st.title("売上ダッシュボード")
data = pd.read_csv("sales_data.csv")
st.line_chart(data)このようなシンプルなコードだけで、機能的なダッシュボードが完成します。
Streamlitの主要なメリット
1. シンプルな学習曲線
Streamlitは、職業プログラマーでなくても扱えるレベルのシンプルさを実現しています。Pythonの基本的な知識があれば、データ分析の経験を活かしてすぐにダッシュボード開発を始められます。
2. 柔軟性とカスタマイズ性
コードベースのアプローチにより、以下の自由度を獲得できます。
- 無限のカスタマイズ可能性 ... ビジネス要件に合致したUIの構築
- 最新技術の活用 ... AIモデルやクラウドサービスとの自由な統合
- 独自ロジックの実装 ... 複雑なビジネスルールの正確な反映
3. バージョン管理とコラボレーション
Gitを使用したコード管理により、以下のメリットを享受できます。
- 変更履歴の完全な追跡 ... 全ての変更が記録され、責任の所在が明確
- チーム開発の効率化 ... ブランチを使った並行開発とマージ
- 品質管理の向上 ... コードレビューによる品質担保
実際の変化:ケーススタディ
| ユースケース | 従来の課題 | Streamlit導入後の変化 |
|---|---|---|
| 製造業: 製品管理ダッシュボード | ・既存BIツールでは製造ラインの複雑な品質基準を表現できない ・リアルタイム監視が不可能で、不良品の早期 発見ができない | ・カスタム品質評価ロジックを実装 ・IoTセンサーからのリアルタイムデータ監視を実現 ・異常検知アルゴリ ズムによる自動アラート機能を追加 |
| EC: 売上分析ダッシュボード | ・複数のデータソース(Web、モバイル、実店舗)の統合が困難 ・予測モデルをBIツールに組み込めない | ・カスタムAPIを通じた全チャネルデータの統合 ・機械学習モデルによる需要予測機能を実装 ・A/Bテスト結 果のリアルタイム分析機能を追加 |
AI時代だからこそのStreamlit
AIとコードベースアプローチの親和性
現在のAI技術の進歩により、非エンジニアでもコード生成が可能になりました。特に、以下の技術との組み合わせでStreamlitの価値が大幅に向上しています。
1. GPTによるコード生成
ChatGPTやGitHub Copilotなどのツールにより、自然言語の指示からアプリケーションコードを生成する事例を目にしたことがあるかもしれません。近年のモデルの進化により、コード生成の精度が飛躍的に向上しています。
その中でも、StreamlitはAIによるコード生成が特別良いフレームワークです。Streamlitはデータの読み込みからデータの変換、可視化までをシンプルなコードで実現できるため、かつ一つのファイルの中に全てのロジックを記述できるため、AIによるコード生成が非常に効果的です。
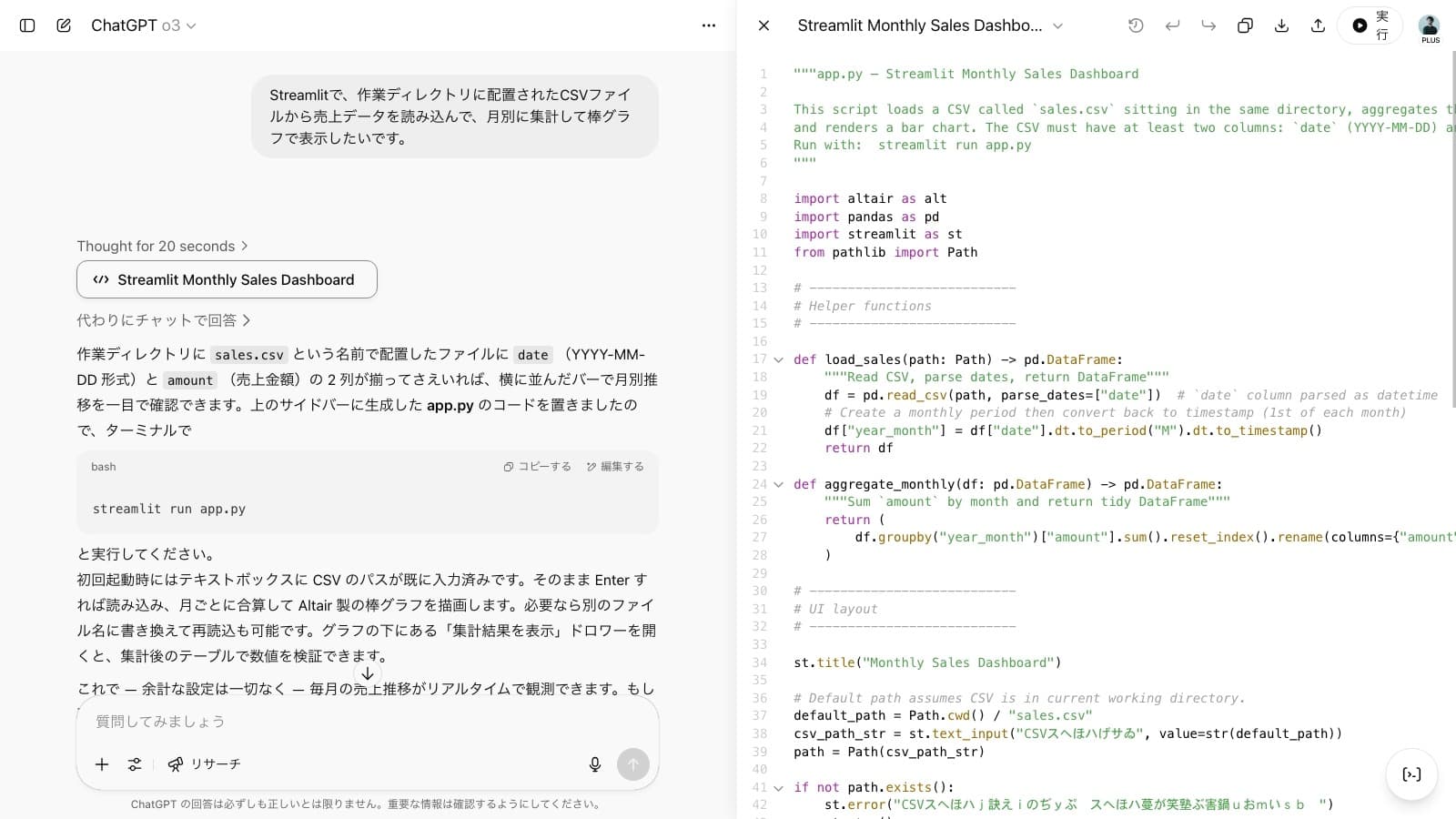
2. "AIを使ったノーコード" 的な開発体験
Claude Codeなどのコーディングエージェントを活用すると、既存のコードベースに対する変更を自然言語で指示することで、非常に高い精度で思い描いた機能を実現できます。以下の様な開発フローで、ノーコードツールの制約を取っ払い、かつコーディングの知識がなくても、直感的にアプリケーションを開発できます。
- 対話型開発 ... 「この機能を追加して」「ここを修正して」といったインタラクティブで直感的な開発体験
- インクリメンタル開発 ... 小さな機能から始めて徐々に拡張
- エラー解決支援 ... エラーメッセージをAIに相談して解決策を取得
3. 最新AIモデルの恩恵を、リリースされたその日から
コードベースのアプローチにより、最新のAI技術を即座に活用できます。改善された最新のAIモデルは、ほとんどの場合コーディング能力に関する能力向上を含んでいます。それらの最新モデルの恩恵をリリースされたその日から活用できるのが、コードベースでBIを開発することの最大のメリットです。
AI活用の具体例
ダッシュボードの開発だけではなく、運用時の動作の中にもAIを自由に活用できる点もコードベースのBIダッシュボードの大きなメリットです。
1. 自然言語クエリ機能
従来のBIダッシュボードでは、データをクエリするSQL文を事前に用意して、ユーザーがそれを選択する形でデータを取得していました。しかし、StreamlitではAIを活用して、ユーザーが自然言語で質問を入力するだけで、AIが自動的にSQLクエリを生成し、データを取得できます。
# 自然言語でデータ分析アプリの基本構造
import streamlit as st
from langchain import OpenAI
st.title("自然言語でデータ分析")
query = st.text_input("質問を入力してください")
if query:
# AIがSQLクエリを生成
llm = OpenAI()
sql_query = llm(f"質問をSQLに変換: {query}")
# 結果を表示
result = execute_query(sql_query)
st.dataframe(result)2. インテリジェントなレポート生成
従来のダッシュボードでは、データの可視化やレポートのフォーマットを事前に定義しておく必要があり、変更するにはダッシュボードを再構築する必要がありました。しかし、StreamlitではAIを活用して、データの分析結果を自動的に要約し、レポートを生成できます。これにより、ユーザーはデータの洞察を迅速に得ることができます。
# AIを活用したレポート生成機能
def generate_insights(data):
insights = ai_analyzer.analyze(data)
st.subheader("AI分析結果")
for insight in insights:
st.write(f"📊 {insight}")Streamlit vs セルフサービス BI:詳細比較
構築コスト
| 観点 | セルフサービス BI | Streamlit |
|---|---|---|
| 初期導入費用 | 高額(数百万円〜) | 無料(オープンソース) |
| ライセンス費用 | ユーザー数×月額課金 | 無料(クラウド費用のみ) |
| 開発工数 | 設定・カスタマイズに時間 | 初回学習後は高速開発 |
| 教育コスト | ツール固有の操作習得 | Python基礎知識で対応 |
Streamlitの優位性 ... 特に中小企業や部門単位での導入において、コスト優位性が顕著です。
運用の良さ
| 観点 | セルフサービス BI | Streamlit |
|---|---|---|
| バージョン管理 | GUI操作による設定変更 変更履歴の追跡が困難 ロールバックが複雑 | Gitによる完全なバージョン管理 変更内容の詳細な記録 簡単なロールバック操作 |
| 環境管理 | 開発・テスト・本番環境の同期が困難 設定の手動移行が必要 | コードベースによる環境の完全な再現 CI/CDパイプラインによる自動デプロイ Docker等による環境の標準化 |
| チームコラボレーション | 同時編集の制限 権限管理の複雑さ | Gitによる並行開発 プルリクエストによるコードレビュー 透明性の高い開発プロセス |
柔軟性・自由度
| 観点 | セルフサービス BI | Streamlit |
|---|---|---|
| カスタマイズ能力 | ベンダー提供機能の組み合わせに限定 独自ロジックの実装が困難 UI/UXのカスタマイズ制限 | 無制限のカスタマイズ可能性 任意のPythonライブラリの活用 カスタマイズ可能なUI |
| データソース対応 | サポートされたデータソースのみ カスタムAPIの連携が困難 | あらゆるデータソースに対応 REST API、GraphQL、WebSocket等 リアルタイムデータストリーミング |
| 分析能力 | 組み込み分析機能に依存 高度な統計分析の制限 | pandas、NumPy、scikit-learn等の活用 最新の機械学習アルゴリズム カスタム分析ロジックの実装 |
AIとの相性
| 観点 | セルフサービス BI | Streamlit |
|---|---|---|
| 統合の容易さ | ベンダーが提供するAI機能のみ 最新モデルへの対応遅延 カスタムモデルの統合困難 | 任意のAI/MLライブラリの活用 最新モデルの即座活用 カスタムモデルの簡単統合 |
| 開発効率 | GUI操作による制約 コード生成AIとの親和性低 | コード生成AIとの高い相性 自然言語からの直接コード生成 反復的な改善プロセス |
次のステップ
本章でStreamlitの価値を理解いただけたら、以下の準備を始めてみましょう。
- 環境準備 - 次章で説明するGitHub Codespacesの基本理解
- Pythonの基礎確認 - データフレーム操作(pandas)の基本的な知識
- 自社データの棚卸し - どのようなデータをダッシュボード化したいかの整理
- AIツールのアカウント準備 - ChatGPT等のコード生成AIへのアクセス確保
次の章「Streamlitの基本概念とセットアップ方法」では、実際に手を動かしながら最初のダッシュボードを構築していきます。プログラミング初心者の方でも安心して進められるよう、ステップバイステップで解説します。